
2024暑期实习
实习内容
- 主要任务:PDF数据提取 (所以…是什么岗位呢?
雾) - 项目回顾
- 项目选型(20240801-20240806):Google现有方案,进行筛选
- 项目深挖(20240807-):对筛选出的方案进行分析
背景
- 为训练行业大模型,需要非常多行业相关语料(数据很多,但缺乏能直接用来训练的数据)
- 电子元器件的数据大多在数据手册中
- 数据手册为 PDF 格式,有很多图/表。传统方法难以解析
- 部分 PDF 是图片,需要 OCR
总的来说,就是手册 -> 结构化数据 -> 模型的过程,以实现RAG(Retreval Augmented Generation)
需求
- 将 PDF 转化为 Markdown 格式
- 准确保留表格结构
1. 项目选型
目前(截至20240806)已经有很多 PDF 解析工具,但大多是针对某一类文档或文档具体部分。
| 项目 | 介绍 | 优点 | 缺点 |
|---|---|---|---|
| nougat | Facbook的学术论文OCR工具 | 没跑出来,不知道 | |
| camelot | PDF表格提取&解析库 | import就能用 | 无法识别非传统表格(合并单元格,表格无边框线) |
| pdfminer.six | PDF解析库 | ||
| PyMuPDF | PDF解析库 | ||
| MinerU | 上海人工智能实验室的开源数据提取工具 | 一站式解决方案,复杂版面分析,多模态信息转换,公式解析 |
经过选型,我认为MinerU项目是最优解
2. 项目详情
MinerU:
一站式开源高质量数据提取工具,支持PDF/网页/多格式电子书提取。
-
项目效果
- 能较准确地识别不同元素,OCR准确率也较高
- 最终输出为markdown格式(标题,段落标题等作为一级标题标出,图/表作为图片插入)
Span与Layout演示
-
项目流程
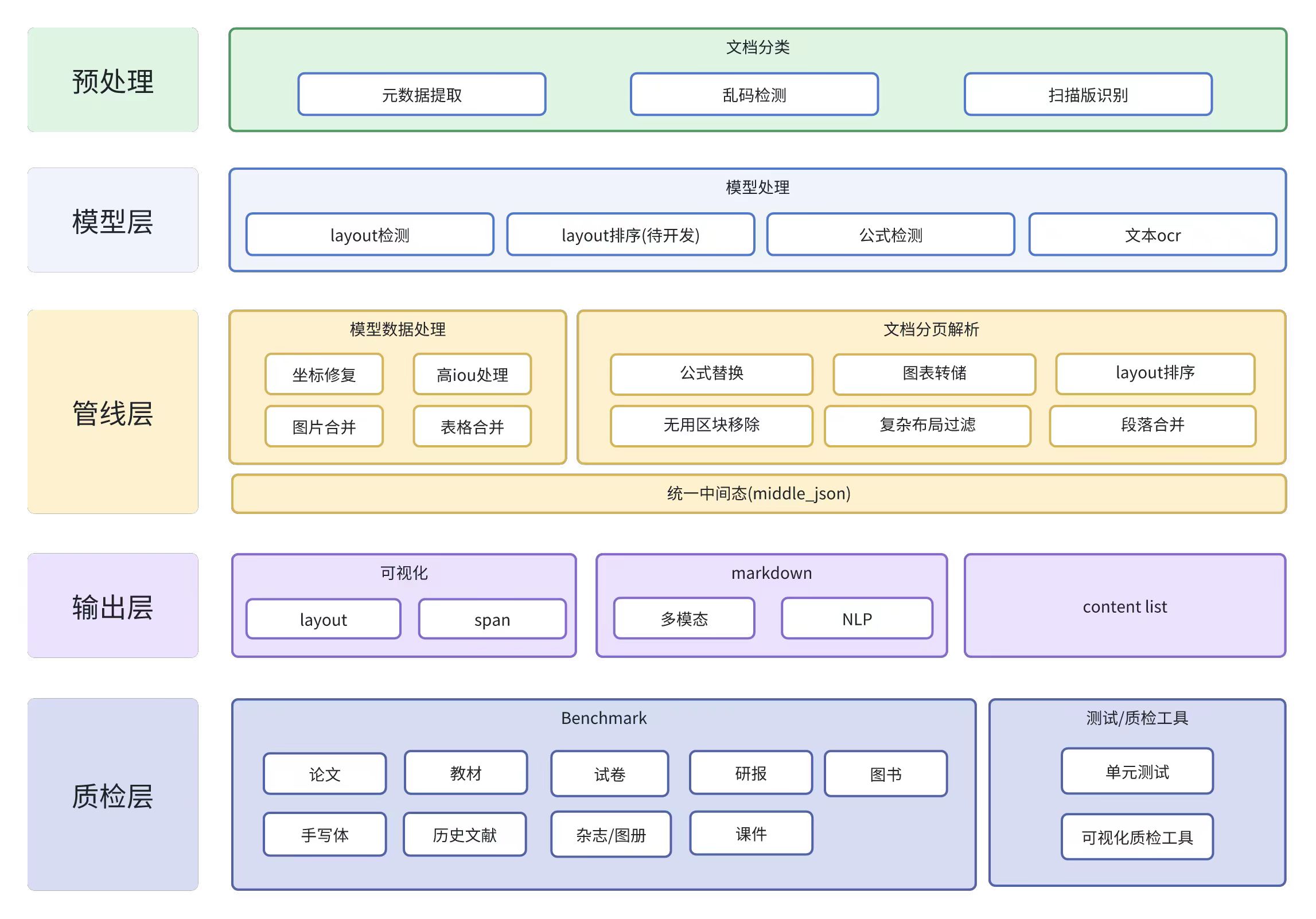
pipeline
demo代码在github仓库中,通过demo和上面那张图可以大致了解处理过程
-
使用局限
- OCR(尤其是表格)耗时长
- 无法将图片转换为自然语言
社区的最新思路
ColPali: 使用视觉语言模型实现高效的文档检索 link
- ColPali: 新的检索模型架构
- ViDoRe: benchmark
传统PDF索引流程(上面那个项目)
-
OCR与解析: 从PDF页面提取出文本。
-
文档布局检测: 检测页面中的不同元素(段落、标题、表格、图像、页眉、页脚)。
-
文本切分与分块: 根据文档的结构,将文本切分为多个块(chunks),每个块代表文档的一部分。这些块通常具有语义上的连贯性,例如一个段落或一组相关的句子。现代的检索系统甚至可能会为视觉丰富的元素(表格、图像)生成自然语言描述,以便更好地嵌入到检索模型中。
-
嵌入生成与索引: 文本块通过预训练的语言模型或其他文本嵌入模型进行编码,将其转化为向量表示。这些向量表示被存储在一个索引中,用于后续的查询匹配。
optimizing the ingestion pipeline yields much greater performance on visually rich document retrieval than optimizing the text embedding model.
ColPali: Just embed the image

基于VLMs(Vision Language Models),根据视觉信息构建索引。
- ViDoRe的评测标准:
- retrieval performance(索引表现): 给出一个query,系统是否返回正确的页面
- low latency during querying(延时)
- high throughput during indexation(吞吐量)
